Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
Welcome to my new blog! I finally transitioned my old static website to a better one using Jekyll. I will mainly blog about science I find interesting at the intersection of AI, neuroscience 🧠, physics and neuromorphic computing 🤖. Stay tuned!
Short description of portfolio item number 1
Short description of portfolio item number 2
Laborieux, A., Bocquet, M., Hirtzlin, T., Klein, J. O., Diez, L. H., Nowak, E., Vianello, E., Portal, J.-M., & Querlioz, D., AICAS, 2020
In this paper we show how to implement a ternary artificial synapse for edge-AI applications
Laborieux, A., Bocquet, M., Hirtzlin, T., Klein, J. O., Nowak, E., Vianello, E., Portal, J.-M., & Querlioz, D., TCAS I, 2020
This is an extended version of our AICAS 2020 paper where we further validate or approach against device variations
Laborieux, A., Ernoult, M., Scellier, B., Bengio, Y., Grollier, J., & Querlioz, D., Frontiers in Neuroscience, 2021

In this paper we show that Equilibrium Propagation can scale to more complex tasks
Laborieux, A., Ernoult, M., Hirtzlin, T., & Querlioz, D., Nature Communications, 2021
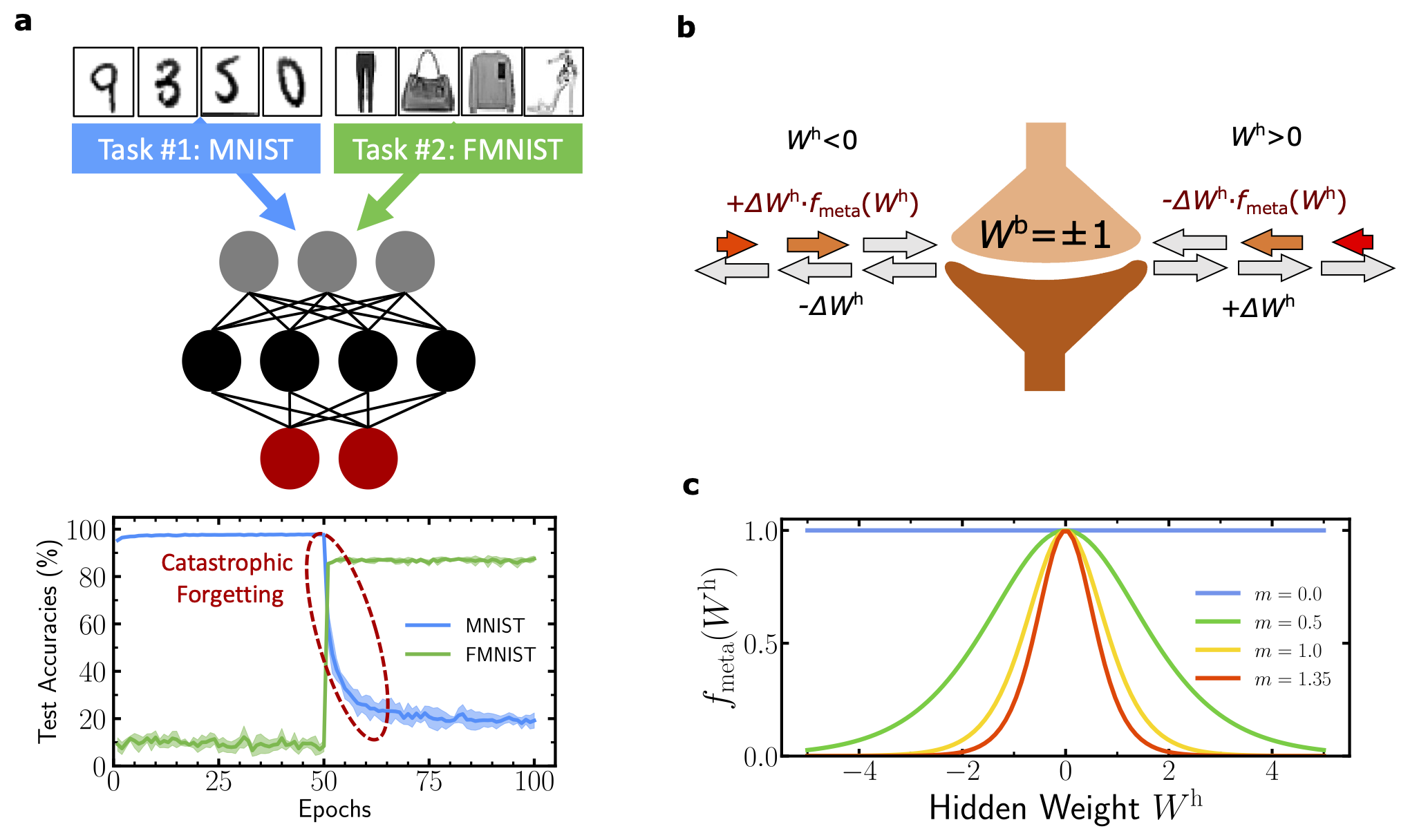
In this work we investigate an interesting and previously unexplored link between the optimization process of binarized neural networks (BNNs) and neuroscience theories of synaptic metaplasticity. We show how to modify the training process of BNNs to mitigate forgetting and achieve continual learning.
Laborieux, A., Université Paris-Saclay, 2021
This is my thesis!
Laborieux, A., & Zenke, F., NeurIPS (Oral), 2022
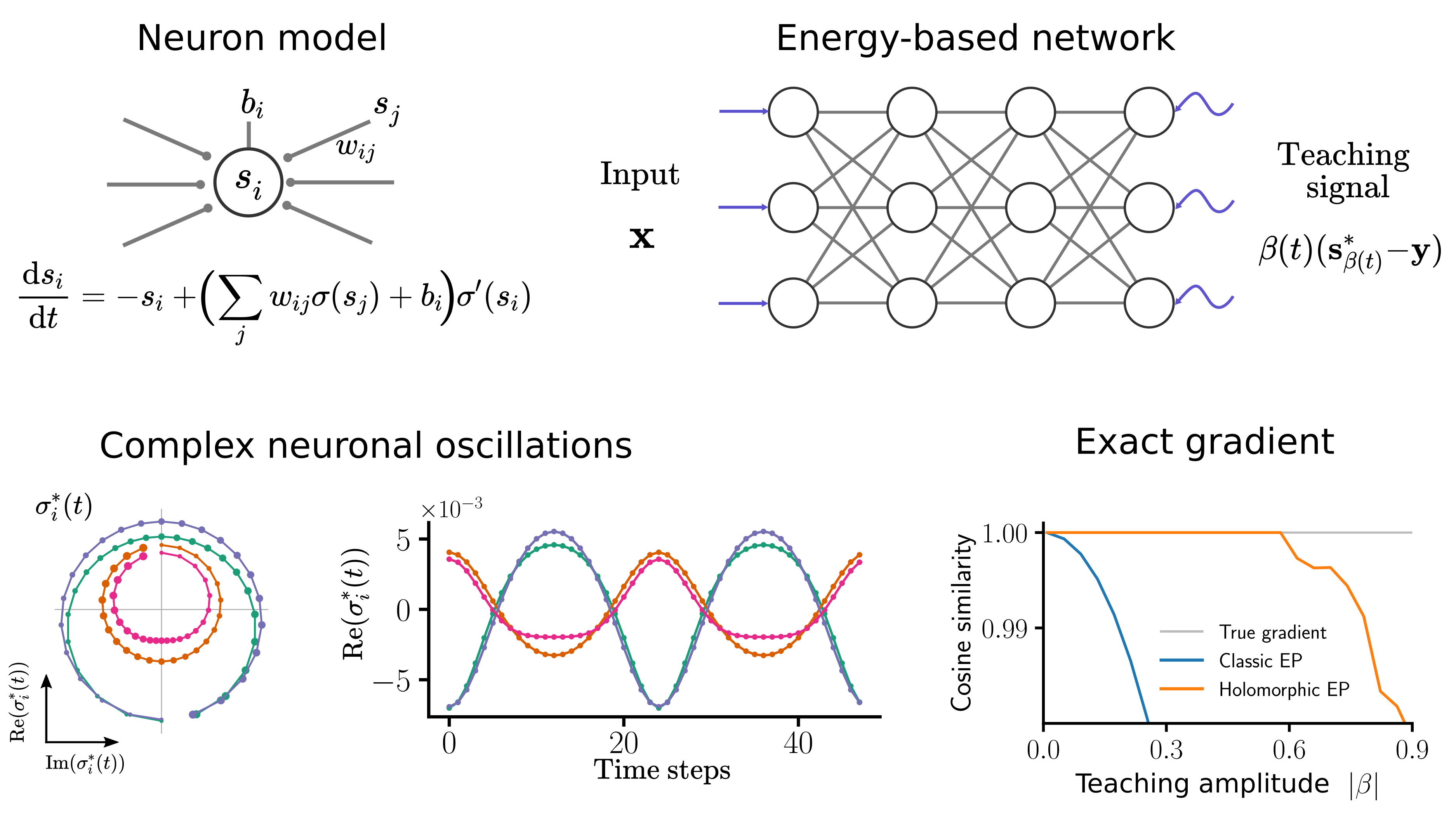
In this paper we extend Equilibrium Propagation to holomorphic networks and show that it can compute the gradient of the loss exactly through finite size neuronal oscillations.
Srinath Halvagal, M.*, Laborieux, A.*, & Zenke, F. (* equal contribution), NeurIPS, 2023
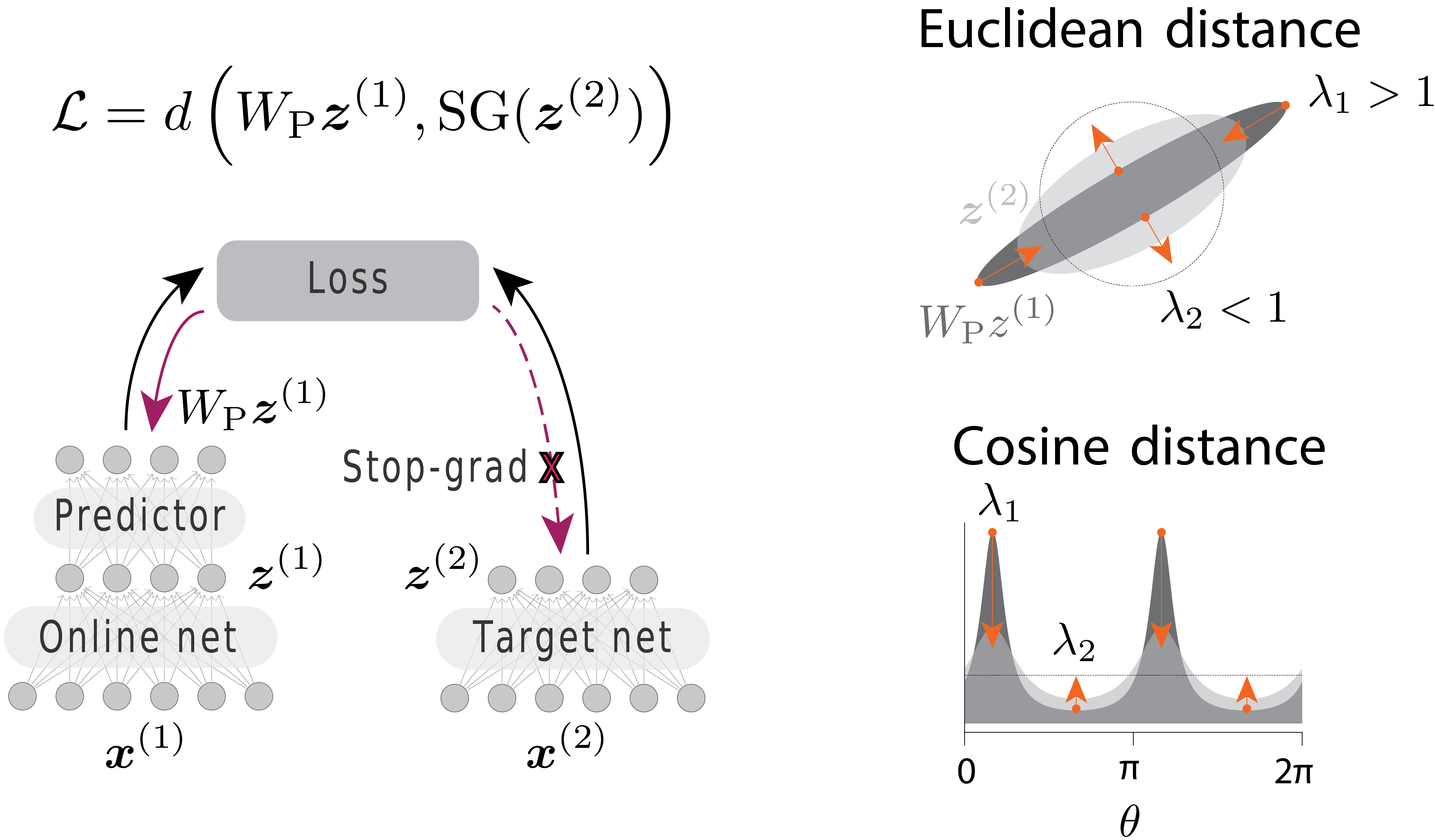
Non contrastive self-supervised learning (SSL) methods learn by making representations invariant to random augmentations of data. However, how the trivial constant output solution (collapse) is avoided remains poorly understood. Building prior theories, we show how non-contrastive SSL might implicitly regularize the variance of learned representation, thereby avoiding collapse. Our theory also suggests new loss functions making learning more robust.
Laborieux, A., & Zenke, F., ICLR, 2024
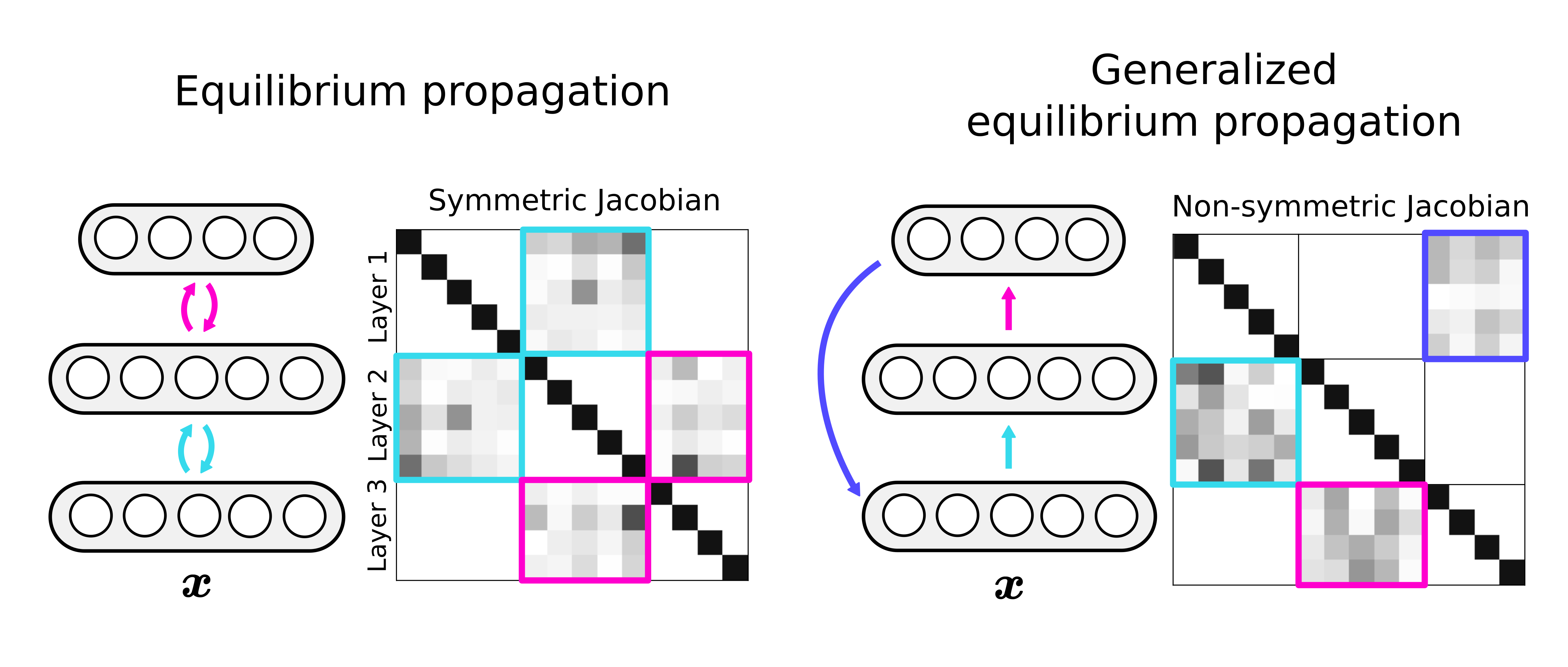
Equilibrium propagation (EP) is a local learning rule with strong theoretical links to gradient-based learning. However, it assumes an energy-based network, which enforces the synaptic connections to be symmetric. This is not only biologically implausible, but also restrictive in terms of architecture design. Here, we extend holomorphic EP to arbitrary converging dynamical systems that may not have an energy function. We quantify how the lack of energy function impacts the accuracy of the gradient estimate, and propose a simple regularization loss that maintains the network’s Jacobian closer to symmetry, which is more general than making the synapses symmetric. These improvements make generalized hEP scale to large scale vision datasets such as ImageNet 32.
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.